COVID-19 Content Portal
COVID-19 Content Portal
public health
Mapping COVID-19
By Lauren Gardner, January 23, 2020
.embed-container {position: relative; padding-bottom: 80%; height: 0; max-width: 100%;} .embed-container iframe, .embed-container object, .embed-container iframe{position: absolute; top: 0; left: 0; width: 100%; height: 100%;} small{position: absolute; z-index: 40; bottom: 0; margin-bottom: -15px;}
Reference: Dong E, Du H, Gardner L. An interactive web-based dashboard to track COVID-19 in real time. Lancet Infect Dis; published online Feb 19. https://doi.org/10.1016/S1473-
Background
On December 31, 2019, the World Health Organization (WHO) was informed of an outbreak of “pneumonia of unknown cause” detected in Wuhan City, Hubei Province, China – the seventh-largest city in China with 11 million residents. As of January 23, there are over 800 cases of 2019-nCoV confirmed globally, including cases in at least 20 regions in China and nine countries/territories. The first reported infected individuals, some of whom showed symptoms as early as December 8, were discovered to be among stallholders from the Wuhan South China Seafood Market. Subsequently, the wet market was closed on Jan 1. The virus causing the outbreak was quickly determined to be a novel coronavirus. On January 10, gene sequencing further determined it to be the new Wuhan coronavirus, namely 2019-nCoV, a betacoronavirus, related to the Middle Eastern Respiratory Syndrome virus (MERS-CoV) and the Severe Acute Respiratory Syndrome virus (SARSCoV). However, the mortality and transmissibility of 2019-nCoV are still unknown, and likely to vary from those of the prior referenced coronaviruses.
Infected travelers (primarily air) are known to be responsible for introductions of the virus outside Wuhan. On Jan 13 Thailand reported the first international case outside China, while the first cases within China, but outside of Wuhan were reported on January 19, in Guangdong and Beijing. On January 20, China’s National Health Commission (NHC) confirmed that the coronavirus can be transmitted between humans. On the same day human infections with 2019-nCoV had also been confirmed in Japan and South Korea, and the following day cases in the U.S. and Taiwan were detected in travelers returning from Wuhan. On January 21 multiple provinces in China were also reporting new cases and infection was confirmed in 15 healthcare workers, with six fatalities reported. Additional travel cases have now been confirmed in Hong Kong, Macau, Singapore and Vietnam. On Jan 22, a WHO emergency committee convened to discuss whether the outbreak should be classified as a public health emergency of international concern (PHEIC) under International Health Regulations, but were initially undecided due to lack of information, before deciding against the declaration.
Of immediate concern is the risk of further transmission resulting from high travel volumes and mass gatherings in celebration of the Chinese New Year on January 24. In attempts to mitigate local transmission within China, unprecedented outbreak control strategies were implemented in (initially) three cities. On 23 January 2020, Wuhan suspended all public transport and air travel (in and out of the city), placing all 11 million city residents under quarantine. On Jan 24, Huanggang and Ezhou, cities adjacent to Wuhan, will also be placed under a similar quarantine, with more cities in China now following suit. Further, many cities have canceled Chinese New Year celebrations.
As Wuhan is a major air transportation hub in central China, various measures have been taken on a global scale to mitigate international spread. Targeted airport screening of passengers traveling from Wuhan was initiated as early as January 1 in Hong Kong and Macau. Taiwan, Singapore and Thailand starting to screen arriving passengers on January 3. In the U.S., the CDC began entry screening of passengers on direct and connecting flights from Wuhan to the three main ports of entry on January 17, 2020, with Atlanta and Chicago soon to be added. On January 23 the U.S. CDC raised its travel notice for Wuhan, China, to the highest of three levels. Additional Pacific and Asian countries including Malaysia, Sri Lanka, Bangladesh and India are now also conducting targeted passenger screening at airports.
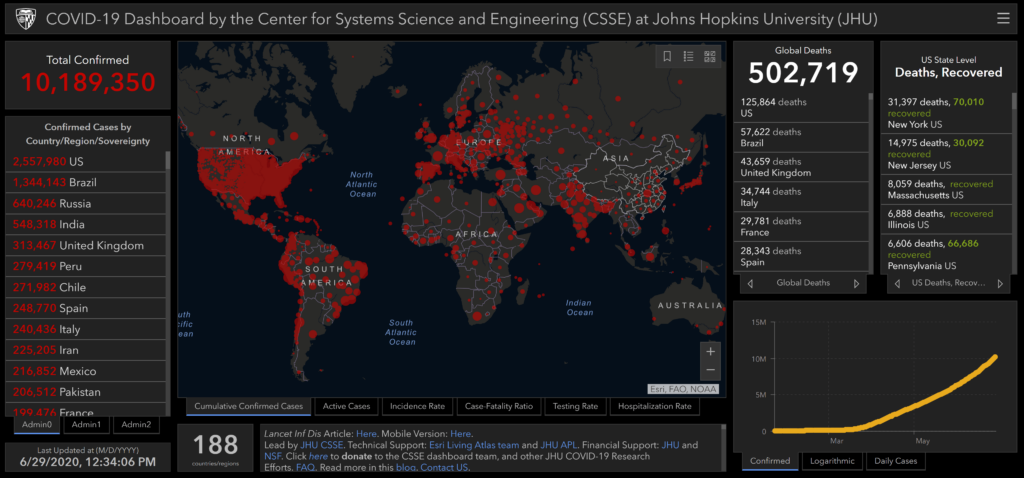
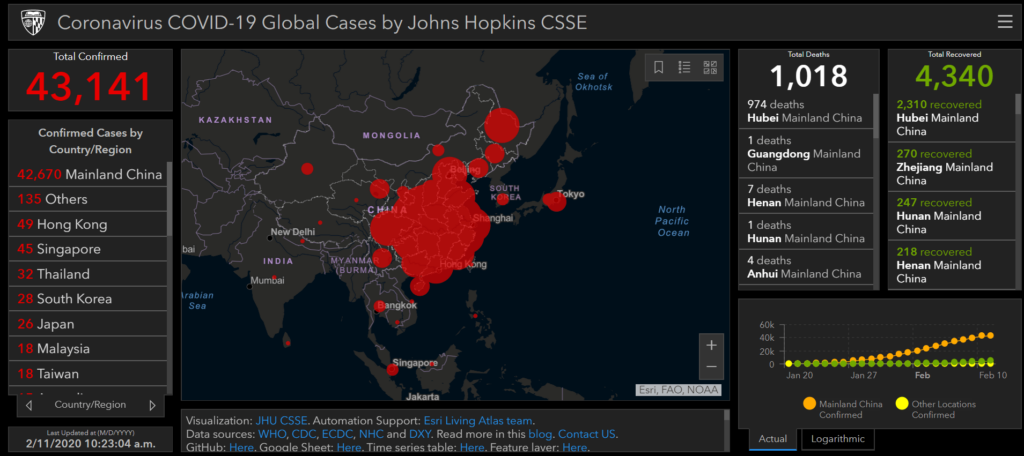
GIS Dashboard (Updated April 27, 2020)
In response to this ongoing public health emergency, we developed an interactive web-based dashboard (static snapshot shown above) hosted by the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University, to visualize and track reported cases in real-time. The dashboard, first shared publicly on January 22, illustrates the location and number of confirmed COVID-19 cases, deaths and recoveries for all affected countries. It was developed to provide researchers, public health authorities and the general public with a user-friendly tool to track the outbreak as it unfolds. Further, all the data collected and displayed is made freely available, initially as google sheets, now in a GitHub repository, along with the feature layers of the dashboard, which are now included in the ESRI Living Atlas.
The dashboard reports cases at the province level in China, county level in the US, state level in Australia and Canada, and at the country level otherwise. From January 22-31 the entire data collection and processing was managed manually. During this period the number of updates were typically conducted twice a day, both morning and night (Eastern Time). As the outbreak evolved, the manual reporting process became unsustainable, and on February 1, we adopted a semi-automated living data stream strategy. Our primary data source was initially DXY, an online platform run by members of the Chinese medical community, which aggregates local media and government reports to provide COVID-19 cumulative case totals in near real-time at the province level in China and country level otherwise. As the outbreak spread outside of China, the set of data sources providing the most reliable and timely case data evolved. We therefore regularly update, replace and supplement the set of data sources we rely on. Currently, DXY,remains the primary source of case data for all provinces in Mainland China, as well as Hong Kong, Macau and Taiwan. Additional data sources are relied upon for reporting on regions outside China. These include U.S. county and state health departments, multiple national government health departments, as well as data aggregating websites including 1point3acres, Worldometers.info, BNO,and the COVID Tracking Project (testing and hospitalizations), which rely on a combination of reporting from local health departments and local media reports. The full list of sources is maintained on our CSSE COVID19 GitHub Repository. All dashboard data curation and updates are coordinated by a team at JHU.
Acknowledgements
Below is a list of the organizations supporting our Center’s COVID-19 mapping and modeling efforts. We are grateful for financial support from JHU, NSF, NIAID and NASA, Bloomberg Philanthropies, Stavros Niarchos Foundation, resource support from AWS, Slack and Github, and for technical support from Esri Living Atlas team and JHU APL.